概念
JavaScript 在浏览器下一般三部分组成:
ECMAscript DOM BOM
W3C 是非标准化组织,制定浏览器规范
ECMAscript:是一种标准,用来标准化 JavaScript 语言,es6、es7 都是其标准化的产物。在浏览器中以 V8,JSCore 等引擎解析。
MDN:Mozilla Developer Network 规范文档
常见 BOM 对象
Navigator:浏览器代码,名称,操作系统,是否在线等
location:hash,hostname 主机路径,port 端口,origin 协议主机端口;支持 reload、replace 等方法。
screen:pixelDepth 等
History:back() forward()等跨网页跳转 pushState()页面不刷新
事件模型
1 | <div id="app"> |
1 | //冒泡:p -> div -> body -> html -> document |
事件委托
利用冒泡实现事件代理
1 | <ul> |
实现懒加载
使用 scroll event 和 getBoundingClientRect 实现
将 img 的 src 属性写入 data-src,监听页面滚动事件,当图片可以看见时(img 元素顶部距离视窗顶部距离小于视窗高度),则加载
data-src 中的图片路径。
1 | <img data-src="./xxx.png" alt /> |
使用 IntersectionObserver 实现
IntersectionObserver是浏览器提供的函数,交叉观察,当目标元素和可视窗口出现交叉区域时,触发事件会触发两次,目标元看见或看不见都会触发
浏览器请求
XHR
1 | // 实例化 |
fetch
1.默认不带 cookie
1 | fetch('http://domain/service', { |
2.错误不会 reject
3.不支持超时设置
4.中止 fetch(借用 AbortController)
Http 缓存
缓存的原理是首次请求之后保存一份请求资源的响应副本,如果判断缓存命中则拦截请求,将之前存储的响应副本返回给用户,从而避免重新发起资源请求
HTTP 缓存可细分为强制缓存和协商缓存,二者最大区别是是否需要向服务器询问从而决定是否发起请求。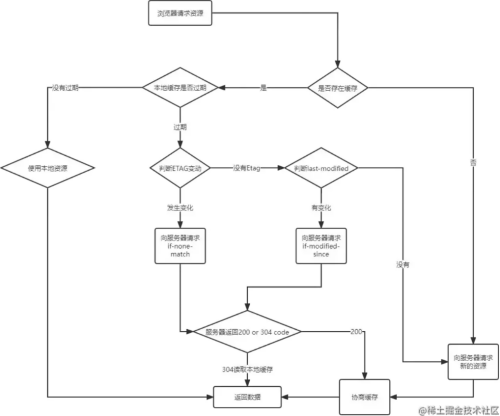
强制缓存
无脑按时间判断是否需要更新,不判断服务器端文件是否更新
协商缓存
基于 last-modified 实现
- 首先在服务器端读出修改时间
- 将读出来的时间赋给响应头的 last-modified 字段
- 最后设置 Cache-control:no-cache
Etag 实现
hash 实现
- 第一次请求时候,服务器端将要返回给客户端的数据通过 Etag 模块进行 hash 生成字符串,这个字符串类似于文件指纹
- 第二次请求是,客户端从缓存读取上一次返回的 Etag,并赋给请求头 if-None-Match 字段
- 服务器端监测 if-None-Match 字段的值与第一步计算的是否一致,一致则返回 304
- 如果不一致则返回 etag 标头和 Cache-Control:no-cache
优劣
精确度 etag 高
耗时 last-modified 更快
服务器优先选择 etag